As the Folsom release of OpenStack is due to be released this week, I've taken the time to update my "Intro to OpenStack Architecture 101" for the official documentation. It merged into the repos yesterday and below is an expanded version of it.
OpenStack Components
There are currently seven core components of OpenStack: Compute, Object Storage, Identity, Dashboard, Block Storage, Network and Image Service. Let's look at each in turn:
- Object Store (codenamed "Swift") allows you to store or retrieve files (but not mount directories like a fileserver). Several companies provide commercial storage services based on Swift. These include KT, Rackspace (from which Swift originated) and Internap. Swift is also used internally at many large companies to store their data.
- Image (codenamed "Glance") provides a catalog and repository for virtual disk images. These disk images are mostly commonly used in OpenStack Compute. While this service is technically optional, any cloud of size will require it.
- Compute (codenamed "Nova") provides virtual servers upon demand. Rackspace and HP provide commercial compute services built on Nova and it is used internally at companies like Mercado Libre and NASA (where it originated).
- Dashboard (codenamed "Horizon") provides a modular web-based user interface for all the OpenStack services. With this web GUI, you can perform most operations on your cloud like launching an instance, assigning IP addresses and setting access controls.
- Identity (codenamed "Keystone") provides authentication and authorization for all the OpenStack services. It also provides a service catalog of services within a particular OpenStack cloud.
- Network (codenamed "Quantum") provides "network connectivity as a service" between interface devices managed by other OpenStack services (most likely Nova). The service works by allowing users to create their own networks and then attach interfaces to them. Quantum has a pluggable architecture to support many popular networking vendors and technologies. Quantum is new in the Folsom release.
- Block Storage (codenamed "Cinder") provides persistent block storage to guest VMs. This project was born from code originally in Nova (the nova-volume service described below). Please note that this is block storage (or volumes) not filesystems like NFS or CIFS share. Cinder is new for the Folsom release.
Comparison Against AWS
Although all of the OpenStack services are made to stand on their own, many users want some form of AWS compatibility for tools, APIs or just familiarity:
- Nova is conceptually similar to EC2. In fact, there is are a variety of ways to provide EC2 API compatibility to it.
- Swift is conceptually similar to S3. It implements a subset of the S3 API in WSGI middleware.
- Glance provides many of the same features as Amazon's AMI catalog.
- Cinder provides block services similar to EBS.
Conceptual Architecture
The OpenStack project as a whole is designed to "deliver(ing) a massively scalable cloud operating system." To achieve this, each of the constituent services are designed to work together to provide a complete Infrastructure as a Service (IaaS). This integration is facilitated through public application programming interfaces (APIs) that each service offers (and in turn can consume). While these APIs allow each of the services to use another service, it also allows an implementer to switch out any service as long as they maintain the API. These are (mostly) the same APIs that are available to end users of the cloud.
Conceptually, you can picture the relationships between the services as so:

- Dashboard ("Horizon") provides a web front end to the other OpenStack services
- Compute ("Nova") stores and retrieves virtual disks ("images") and associated metadata in Image ("Glance")
- Network ("Quantum") provides virtual networking for Compute.
- Block Storage ("Cinder") provides storage volumes for Compute.
- Image ("Glance") can store the actual virtual disk files in the Object Store("Swift")
- All the services authenticate with Identity ("Keystone")
This is a stylized and simplified view of the architecture, assuming that the implementer is using all of the services together in the most common configuration. It also only shows the "operator" side of the cloud -- it does not picture how consumers of the cloud may actually use it. For example, many users will access object storage heavily (and directly).
Logical Architecture
As you can imagine, the logical architecture is far more complicated than the conceptual architecture shown above. As with any service-oriented architecture, diagrams quickly become "messy" trying to illustrate all the possible combinations of service communications. The diagram below, illustrates the most common architecture of an OpenStack-based cloud. However, as OpenStack supports a wide variety of technologies, it does not represent the only architecture possible.

This picture is consistent with the conceptual architecture above in that:
- End users can interact through a common web interface (Horizon) or directly to each service through their API
- All services authenticate through a common source (facilitated through Keystone)
- Individual services interact with each other through their public APIs (except where privileged administrator commands are necessary)
In the sections below, we'll delve into the architecture for each of the services.
Dashboard
Horizon is a modular Django web application that provides an end user and administrator interface to OpenStack services.

As with most web applications, the architecture is fairly simple:
Horizon is usually deployed via mod_wsgi in Apache. The code itself is separated into a reusable python module with most of the logic (interactions with various OpenStack APIs) and presentation (to make it easily customizable for different sites).
A database (configurable as to which one). As it relies mostly on the other services for data, it stores very little data of its own.
From a network architecture point of view, this service will need to be customer accessible as well as be able to talk to each service's public APIs. If you wish to use the administrator functionality (i.e. for other services), it will also need connectivity to their Admin API endpoints (which should not be customer accessible).
Compute
Nova is the most complicated and distributed component of OpenStack. A large number of processes cooperate to turn end user API requests into running virtual machines. Below is a list of these processes and their functions:
- nova-api accepts and responds to end user compute API calls. It supports OpenStack Compute API, Amazon's EC2 API and a special Admin API (for privileged users to perform administrative actions). It also initiates most of the orchestration activities (such as running an instance) as well as enforces some policy (mostly quota checks).
- The nova-compute process is primarily a worker daemon that creates and terminates virtual machine instances via hypervisor's APIs (XenAPI for XenServer/XCP, libvirt for KVM or QEMU, VMwareAPI for VMware, etc.). The process by which it does so is fairly complex but the basics are simple: accept actions from the queue and then perform a series of system commands (like launching a KVM instance) to carry them out while updating state in the database.
- The nova-volume manages the creation, attaching and detaching of persistent volumes to compute instances (similar functionality to Amazon’s Elastic Block Storage). It can use volumes from a variety of providers such as iSCSI or Rados Block Device in Ceph. A new OpenStack projects, Cinder, will eventually replace nova-volume functionality. In the Folsom release, nova-volume and the Block Storage service will have similar functionality.
- The nova-network worker daemon is very similar to nova-compute and nova-volume. It accepts networking tasks from the queue and then performs tasks to manipulate the network (such as setting up bridging interfaces or changing iptables rules). This functionality is being migrated to Quantum, a separate OpenStack service. In the Folsom release, much of the functionality will be duplicated between nova-network and Quantum.
- The nova-schedule process is conceptually the simplest piece of code in OpenStack Nova: take a virtual machine instance request from the queue and determines where it should run (specifically, which compute server host it should run on).
- The queue provides a central hub for passing messages between daemons. This is usually implemented with RabbitMQ today, but could be any AMPQ message queue (such as Apache Qpid). New to the Folsom release is support for Zero MQ (note: I've only included this so that Eric Windisch won't be hounding me mercilessly about it's omission).
- The SQL database stores most of the build-time and run-time state for a cloud infrastructure. This includes the instance types that are available for use, instances in use, networks available and projects. Theoretically, OpenStack Nova can support any database supported by SQL-Alchemy but the only databases currently being widely used are sqlite3 (only appropriate for test and development work), MySQL and PostgreSQL.
- Nova also provides console services to allow end users to access their virtual instance's console through a proxy. This involves several daemons (nova-console, nova-vncproxy and nova-consoleauth).
Nova interacts with many other OpenStack services: Keystone for authentication, Glance for images and Horizon for web interface. The Glance interactions are central. The API process can upload and query Glance while nova-compute will download images for use in launching images.
Object Store
The swift architecture is very distributed to prevent any single point of failure as well as to scale horizontally. It includes the following components:
- Proxy server (swift-proxy-server) accepts incoming requests via the OpenStack Object API or just raw HTTP. It accepts files to upload, modifications to metadata or container creation. In addition, it will also serve files or container listing to web browsers. The proxy server may utilize an optional cache (usually deployed with memcache) to improve performance.
- Account servers manage accounts defined with the object storage service.
- Container servers manage a mapping of containers (i.e folders) within the object store service.
- Object servers manage actual objects (i.e. files) on the storage nodes.
The object store can also serve static web pages and objects via HTTP. In fact, the diagrams in this blog post are being served out of Rackspace Cloud's Swift service.
Authentication is handled through configurable WSGI middleware (which will usually be Keystone).
Image Store
The Glance architecture has stayed relatively stable since the Cactus release. The biggest architectural change has been the addition of authentication, which was added in the Diablo release. Just as a quick reminder, Glance has four main parts to it:
- glance-api accepts Image API calls for image discovery, image retrieval and image storage.
- glance-registry stores, processes and retrieves metadata about images (size, type, etc.).
- A database to store the image metadata. Like Nova, you can choose your database depending on your preference (but most people use MySQL or SQlite).
- A storage repository for the actual image files. In the diagram above, Swift is shown as the image repository, but this is configurable. In addition to Swift, Glance supports normal filesystems, RADOS block devices, Amazon S3 and HTTP. Be aware that some of these choices are limited to read-only usage.
There are also a number of periodic process which run on Glance to support caching. The most important of these is the replication services, which ensures consistency and availability through the cluster. Other periodic processes include auditors, updaters and reapers.
As you can see from the diagram in the Conceptual Architecture section, Glance serves a central role to the overall IaaS picture. It accepts API requests for images (or image metadata) from end users or Nova components and can store its disk files in the object storage service, Swift.
Identity
Keystone provides a single point of integration for OpenStack policy, catalog, token and authentication.
- keystone handles API requests as well as providing configurable catalog, policy, token and identity services.
- Each Keystone function has a pluggable backend which allows different ways to use the particular service. Most support standard backends like LDAP or SQL, as well as Key Value Stores (KVS).
Most people will use this as a point of customization for their current authentication services.
Network
Quantum provides "network connectivity as a service" between interface devices managed by other OpenStack services (most likely Nova). The service works by allowing users to create their own networks and then attach interfaces to them. Like many of the OpenStack services, Quantum is highly configurable due to it's plug-in architecture. These plug-ins accommodate different networking equipment and software. As such, the architecture and deployment can vary dramatically. In the above architecture, a simple Linux networking plug-in is shown.
- quantum-server accepts API requests and then routes them to the appropriate quantum plugin for action.
- Quantum plugins and agents perform the actual actions such as plugging and unplugging ports, creating networks or subnets and IP addressing. These plugins and agents differ depending on the vendor and technologies used in the particular cloud. Quantum ships with plugins and agents for: Cisco virtual and physical switches, Nicira NVP product, NEC OpenFlow products, Open vSwitch, Linux bridging and the Ryu Network Operating System. Midokua also provides a plug-in for Quantum integration. The common agents are L3 (layer 3), DHCP (dynamic host IP addressing) and the specific plug-in agent.
- Most Quantum installations will also make use of a messaging queue to route information between the quantum-server and various agents as well as a database to store networking state for particular plugins.
Quantum will interact mainly with Nova, where it will provide networks and connectivity for its instances.
Block Storage
Cinder separates out the persistent block storage functionality that was previously part of Openstack Compute (in the form of nova-volume) into it's own service. The OpenStack Block Storage API allows for manipulation of volumes, volume types (similar to compute flavors) and volume snapshots.
- cinder-api accepts API requests and routes them to cinder-volume for action.
- cinder-volume acts upon the requests by reading or writing to the Cinder database to maintain state, interacting with other processes (like cinder-scheduler) through a message queue and directly upon block storage providing hardware or software. It can interact with a variety of storage providers through a driver architecture. Currently, there are drivers for IBM, SolidFire, NetApp, Nexenta, Zadara, linux iSCSI and other storage providers.
- Much like nova-scheduler, the cinder-scheduler daemon picks the optimal block storage provider node to create the volume on.
- Cinder deployments will also make use of a messaging queue to route information between the cinder processes as well as a database to store volume state.
Like Quantum, Cinder will mainly interact with Nova, providing volumes for its instances.
Future Projects
A number of projects are in the work for future versions of OpenStack. They include:
- Ceilometer is a metering project. The project offers metering information and the ability to code more ways to know what has happened on an OpenStack cloud. While it provides metering, it is not a billing project. A full billing solution requires metering, rating, and billing. Metering lets you know what actions have taken place, rating enables pricing and line items, and billing gathers the line items to create a bill to send to the consumer and collect payment. Ceilometer is available as a preview.
- Heat provides a REST API to orchestrate multiple cloud applications implementing standards such as AWS CloudFormation.
What is Windows Azure?
The Components of Windows Azure
To understand what Windows Azure offers, it's useful to group its services into distinct categories. Figure 1 shows one way to do this.

Execution Models
One of the most basic things a cloud platform does is execute applications. Windows Azure provides three options for doing this.

Each of these three approaches-Virtual Machines, Web Sites, and Cloud Services-can be used separately. You can also combine them to create an application that uses two or more of these options together.
Virtual Machines
The ability to create a virtual machine on demand, whether from a standard image or from one you supply, can be very useful. Add the ability to pay for this VM by the hour, and it's even more useful. This approach, commonly known as Infrastructure as a Service (IaaS), is what Windows Azure Virtual Machines provides.Web Sites
One of the most common things that people do in the cloud is run web sites and web applications. Windows Azure Virtual Machines allows this, but it still leaves you with the responsibility of administering one or more VMs. What if you just want a web site where somebody else takes care of the administrative work for you?Cloud Services
Suppose you want to build a cloud application that can support lots of simultaneous users, doesn't require much administration, and never goes down. You might be an established software vendor, for example, that's decided to embrace Software as a Service (SaaS) by building a version of one of your applications in the cloud. Or you might be a start-up creating a consumer application that you expect will grow fast. If you're building on Windows Azure, which execution model should you use?Windows Azure Web Sites allows creating this kind of web application, but there are some constraints. You don't have administrative access, for example, which means that you can't install arbitrary software. Windows Azure Virtual Machines gives you lots of flexibility, including administrative access, and you certainly can use it to build a very scalable application, but you'll have to handle many aspects of reliability and administration yourself. What you'd like is an option that gives you the control you need but also handles most of the work required for reliability and administration.
Data Management
Applications need data, and different kinds of applications need different kinds of data. Because of this, Windows Azure provides several different ways to store and manage data.
One of these has already been mentioned: the ability to run SQL Server or another DBMS in a VM created with Windows Azure Virtual Machines. (It's important to realize that this option isn't limited to relational systems; you're also free to run NoSQL technologies such as MongoDB and Cassandra.) Running your own database system is straightforward-it replicates what we're used to in our own datacenters-but it also requires handling the administration of that DBMS. To make life easier, Windows Azure provides three data management options that are largely managed for you.

Each of the three options addresses a different need: relational storage, fast access to potentially large amounts of simple typed data, and unstructured binary storage. In all three cases, data is automatically replicated across three different computers in a Windows Azure datacenter to provide high availability. It's also worth pointing out that all three options can be accessed either by Windows Azure applications or by applications running elsewhere, such as your on-premises datacenter, your laptop, or your phone. And however you apply them, you pay for all Windows Azure data management services based on usage, including a gigabyte-per-month charge for stored data.
SQL Database
For relational storage, Windows Azure provides SQL Database. Formerly called SQL Azure, SQL Database provides all of the key features of a relational database management system, including atomic transactions, concurrent data access by multiple users with data integrity, ANSI SQL queries, and a familiar programming model. Like SQL Server, SQL Database can be accessed using Entity Framework, ADO.NET, JDBC, and other familiar data access technologies. It also supports most of the T-SQL language, along with SQL Server tools such as SQL Server Management Studio. For anybody familiar with SQL Server (or another relational database), using SQL Database is straightforward.Tables
Suppose you want to create a Windows Azure application that needs fast access to typed data, maybe lots of it, but doesn't need to perform complex SQL queries on this data. For example, imagine you're creating a consumer application that needs to store customer profile information for each user. Your app is going to be very popular, so you need to allow for lots of data, but you won't do much with this data beyond storing it, then retrieving it in simple ways. This is exactly the kind of scenario where Windows Azure Tables makes sense.Blobs
The third option for data management, Windows Azure Blobs, is designed to store unstructured binary data. Like Tables, Blobs provides inexpensive storage, and a single blob can be as large as one terabyte. An application that stores video, for example, or backup data or other binary information can use blobs for simple, cheap storage. Windows Azure applications can also use Windows Azure drives, which let blobs provide persistent storage for a Windows file system mounted in a Windows Azure instance. The application sees ordinary Windows files, but the contents are actually stored in a blob.Networking
Windows Azure runs today in several datacenters spread across the United States, Europe, and Asia. When you run an application or store data, you can select one or more of these datacenters to use. You can also connect to these datacenters in various ways:
- You can use Windows Azure Virtual Network to connect your own on-premises local network to a defined set of Windows Azure VMs.
- If your Windows Azure application is running in multiple datacenters, you can use Windows Azure Traffic Manager to route requests from users intelligently across instances of the application.

Virtual Network
One useful way to use a public cloud is to treat it as an extension of your own datacenter. Because you can create VMs on demand, then remove them (and stop paying) when they're no longer needed, you can have computing power only when you want it. And since Windows Azure Virtual Machines lets you can create VMs running SharePoint, Active Directory, and other familiar on-premises software, this approach can work with the applications you already have.Traffic Manager
A Windows Azure application with users in just a single part of the world might run in only one Windows Azure datacenter. An application with users scattered around the world, however, is more likely to run in multiple datacenters, maybe even all of them. In this second situation, you face a problem: How do you intelligently assign users to application instances? Most of the time, you probably want each user to access the datacenter closest to her, since it will likely give her the best response time. But what if that copy of the application is overloaded or unavailable? In this case, it would be nice to route her request automatically to another datacenter. This is exactly what's done by Windows Azure Traffic Manager.Business Analytics
Analyzing data is a fundamental part of how businesses use information technology. A cloud platform provides a pool of on-demand, pay-per-use resources, which makes it a good foundation for this kind of computing. Accordingly, Windows Azure provides two options for business analytics. Figure 5 illustrates the choices.

Analyzing data can take many forms, and so these two options are quite different. It's worth looking at each one separately.
SQL Reporting
One of the most common ways to use stored data is to create reports based on that data. To let you do this with data in SQL Database, Windows Azure provides SQL Reporting. A subset of the reporting services included with SQL Server, SQL Reporting lets you build reporting into applications running on Windows Azure or on premises. The reports you create can be in various formats, including HTML, XML, PDF, Excel, and others, and they can be embedded in applications or viewed via a web browser.Hadoop
For many years, the bulk of data analysis has been done on relational data stored in a data warehouse built with a relational DBMS. This kind of business analytics is still important, and it will be for a long time to come. But what if the data you want to analyze is so big that relational databases just can't handle it? And suppose the data isn't relational? It might be server logs in a datacenter, for example, or historical event data from sensors, or something else. In cases like this, you have what's known as a big data problem. You need another approach.The dominant technology today for analyzing big data is Hadoop. An Apache open source project, this technology stores data using the Hadoop Distributed File System (HDFS), then lets developers create MapReduce jobs to analyze that data. HDFS spreads data across multiple servers, then runs chunks of the MapReduce job on each one, letting the big data be processed in parallel.
Messaging
No matter what it's doing, code frequently needs to interact with other code. In some situations, all that's needed is basic queued messaging. In other cases, more complex interactions are required. Windows Azure provides a few different ways to solve these problems.

Queues
Queuing is a simple idea: One application places a message in a queue, and that message is eventually read by another application. If your application needs just this straightforward service, Windows Azure Queues might be the best choice.One common use of Queues today is to let a web role instance communicate with a worker role instance within the same Cloud Services application. For example, suppose you create a Windows Azure application for video sharing. The application consists of PHP code running in a web role that lets users upload and watch videos, together with a worker role implemented in C# that translates uploaded video into various formats. When a web role instance gets a new video from a user, it can store the video in a blob, then send a message to a worker role via a queue telling it where to find this new video. A worker role instance-it doesn't matter which one-will then read the message from the queue and carry out the required video translations in the background. Structuring an application in this way allows asynchronous processing, and it also makes the application easier to scale, since the number of web role instances and worker role instances can be varied independently.
Service Bus
Whether they run in the cloud, in your data center, on a mobile device, or somewhere else, applications need to interact. The goal of Windows Azure Service Bus is to let applications running pretty much anywhere exchange data.As Figure 6 shows, Service Bus provides a queuing service. This service isn't identical to the Queues just described, however. Unlike Windows Azure Queues, for example, Service Bus provides a publish-and-subscribe mechanism. An application can send messages to a topic, while other applications can create subscriptions to this topic. This allows one-to-many communication among a set of applications, letting the same message be read by multiple recipients. And queuing isn't the only option: Service Bus also allows direct communication through its relay service, providing a secure way to interact through firewalls.
Caching
Applications tend to access the same data over and over. One way to improve performance is to keep a copy of that data closer to the application, minimizing the time needed to retrieve it. Windows Azure provides two different services for doing this: in-memory caching of data used by Windows Azure applications and a content delivery network (CDN) that caches blob data on disk closer to its users.

Caching
Accessing data stored in any of Windows Azure's data management services-SQL Database, Tables, or Blobs-is quite fast. Yet accessing data stored in memory is even faster. Because of this, keeping an in-memory copy of frequently accessed data can improve application performance. You can use Windows Azure's in-memory Caching to do this.CDN
Suppose you need to store blob data that will be accessed by users around the world. Maybe it's a video of the latest World Cup match, for instance, or driver updates, or a popular e-book. Storing a copy of the data in multiple Windows Azure datacenters will help, but if there are lots of users, it's probably not enough. For even better performance, you can use the Windows Azure CDN.Identity
Working with identity is part of most applications. For example, knowing who a user is lets an application decide how it should interact with that user. To help you do this, Microsoft provides Windows Azure Active Directory.
Like most directory services, Windows Azure Active Directory stores information about users and the organizations they belong to. It lets users log in, then supplies them with tokens they can present to applications to prove their identity. It also allows synchronizing user information with Windows Server Active Directory running on premises in your local network. While the mechanisms and data formats used by Windows Azure Active Directory aren’t identical with those used in Windows Server Active Directory, the functions it performs are quite similar.
High-Performance Computing
One of the most attractive ways to use a cloud platform is for high-performance computing (HPC), The essence of HPC is executing code on many machines at the same time. On Windows Azure, this means running many virtual machines simultaneously, all working in parallel to solve some problem. Doing this requires some way to schedule applications, i.e., to distribute their work across these instances. To allow this, Windows Azure provides the HPC Scheduler.
Media
Video makes up a large part of Internet traffic today, and that percentage will be even larger tomorrow. Yet providing video on the web isn't simple. There are lots of variables, such as the encoding algorithm and the display resolution of the user's screen. Video also tends to have bursts in demand, like a Saturday night spike when lots of people decide they'd like to watch an online movie.
Given its popularity, it's a safe bet that many new applications will be created that use video. Yet all of them will need to solve some of the same problems, and making each one solve those problems on its own makes no sense. A better approach is to create a platform that provides common solutions for many applications to use. And building this platform in the cloud has some clear advantages. It can be broadly available on a pay-as-you-go basis, and it can also handle the variability in demand that video applications often face.
Windows Azure Media Services addresses this problem. It provides a set of cloud components that make life easier for people creating and running applications using video and other media.

As the figure shows, Media Services provides a set of components for applications that work with video and other media. For example, it includes a media ingest component to upload video into Media Services (where it's stored in Windows Azure Blobs), an encoding component that supports various video and audio formats, a content protection component that provides digital rights management, a component for inserting ads into a video stream, components for streaming, and more. Microsoft partners can also provide components for the platform, then have Microsoft distribute those components and bill on their behalf.
Commerce
The rise of Software as a Service is transforming how we create applications. It's also transforming how we sell applications. Since a SaaS application lives in the cloud, it makes sense that its potential customers should look for solutions online. And this change applies to data as well as to applications. Why shouldn't people look to the cloud for commercially available datasets? Microsoft addresses both of these concerns with Windows Azure Marketplace, illustrated in Figure 9.

Potential customers can search the Marketplace to find Windows Azure applications that meet their needs, then sign up to use them either through the application's creator or directly through the Marketplace. Customers can search the Marketplace for commercial datasets as well, including demographic data, financial data, geographic data, and more. When they find something they like, they can access it either from the vendor or directly through the Marketplace. Applications can also use the Bing Search API through the Marketplace, giving them access to the results of web searches.
SDKs
Back in 2008, the very first pre-release version of Windows Azure supported only .NET development. Today, however, you can create Windows Azure applications in pretty much any language. Microsoft currently provides language-specific SDKs for .NET, Java, PHP, Node.js, and Python. There's also a general Windows Azure SDK that provides basic support for any language, such as C++.
These SDKs help you build, deploy, and manage Windows Azure applications. They're available either from www.windowsazure.com or GitHub, and they can be used with Visual Studio and Eclipse. Windows Azure also offers command line tools that developers can use with any editor or development environment, including tools for deploying applications to Windows Azure from Linux and Macintosh systems.
What is Amazon Web Services?
AWS provides a flexible, cost-effective,
scalable, and easy-to-use cloud computing platform that is suitable for
research, educational use, individual use, and organizations of all sizes. It’s
easy to access AWS cloud services via the Internet. Because the AWS cloud
computing model allows you to pay for services on-demand and to use as much or
as little at any given time as you need, you can replace up-front capital
infrastructure expenses with low variable costs that scale as your needs
change. AWS offers services in many areas to fit your needs, as shown in the
diagram.

EC2 – Elastic Computing
Amazon has procured a large number of commoditized Intel boxes running virtualization software Xen. On top of Xen, Linux or Windows can be run as the guest OS . The guest operating system can have many variations with different set of software packages installed.

Each configuration is bundled as a custom machine image (called AMI). Amazon host a catalog of AMI for the users to choose from. Some AMI is free while other requires a usage charge. User can also customize their own setup by starting from a standard AMI, make their special configuration changes and then create a specific AMI that is customized for their specific needs. The AMIs are stored in Amazon’s storage subsystem S3.
Amazon also classifies their machines in terms of their processor power (no of cores, memory and disk size) and charged their usage at a different rate. These machines can be run in different network topology specified by the users. There is an “availability zone” concept which is basically a logical data center. “Availability zone” has no interdependency and is therefore very unlikely to fail at the same time. To achieve high availability, users should consider putting their EC2 instances in different availability zones.
“Security Group” is the virtual firewall of Amazon EC2 environment. EC2 instances can be grouped under “security group” which specifies which port is open to which incoming range of IP addresses. So EC2 instances that running applications at various level of security requirements can be put into appropriated security groups and managed using ACL (access control list). Somewhat very similar to what network administrator configure their firewalls.
User can start the virtual machine (called an EC2 instance) by specifying the AMI, the machine size, the security group, and its authentication key via command line or an HTTP/XML message. So it is very easy to startup the virtual machine and start running the user’s application. When the application completes, the user can also shutdown the EC2 instance via command line or HTTP/XML message. The user is only charged for the actual time when the EC2 instance is running.
One of the issue of extremely dynamic machine configuration (such as EC2) is that a lot of configuration setting is transient and does not survive across reboot. For example, the node name and IP address may have been changed, all the data stored in local files is lost. Latency and network bandwidth between machines may also have changed. Fortunately, Amazon provides a number of ways to mitigate these issues
- By paying some charge, user can reserve a stable IP address, called “elastic IP”, which can be attached to EC2 instance after they bootup. External facing machine is typically done this way.
- To deal with data persistence, Amazon also provides a logical network disk, called “elastic block storage” to store the data. By paying some charges, EBS is reserved for the user and it survives across EC2 reboots. User can attach the EBS to EC2 instances after the reboot.
S3 – Simple Storage Service
Amazon S3 provides a HTTP/XML services to save and retrieve content. It provides a file system-like metaphor where “objects” are group under “buckets”. Based on a REST design, each object and bucket has its own URL.
With HTTP verbs (PUT, GET, DELETE, POST), user can create a bucket, list all the objects within the bucket, create object within a bucket, retrieve an object, remove an object, remove a bucket … etc.
Under S3, each object has a unique URI which serves as its key. There is no query mechanism in S3 and User has to lookup the object by its key. Each object is stored as an opaque byte array with maximum 5GB size. S3 also provides an interesting partial object retrieval mechanism by specifying the ranges of bytes in the URL.
However, partial put is not current support but it can be simulated by breaking the large object into multiple small objects and then do the assembly at the app level. Breaking down the object also help to speed up the upload and download by doing the data transfer in parallel.
Within Amazon S3, each S3 objects are replicated across 2 (or more) data center and also cache at the edge for fast retrieval.
Amazon S3 is based on an “eventual consistent” model which means it is possible that an application won’t see the change it just made. Therefore, some degree of tolerance of inconsistent view is required by the application. Application should avoid the situation of having two concurrent modifications to the same object. And application should wait for some time between updates, and also should expect all the data it reads is potentially stale for few seconds.
There is also no versioning concept in S3, but it is not hard to build one on top of S3.
EBS – Elastic Block Storage
Based on RAID disks, EBS provides a persistent block storage device for data persistence where user can attach it to a running EC2 instance within the same availability zone. EBS is typically used as a file system that is mounted to EC2 instance, or as raw devices for database.
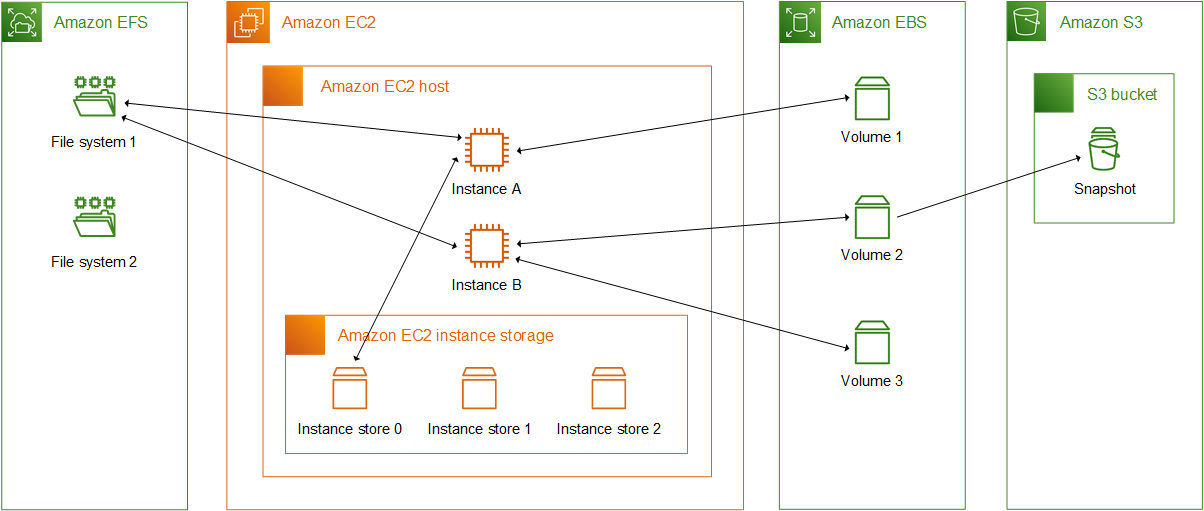
Although EBS is a network devices to the EC2 instance, benchmark from Amazon shows that it has higher performance than local disk access. Unlike S3 which is based on eventual consistent model, EBS provides strict consistency where latest updates are immediately available.
SimpleDB – queriable data storage
Unlike S3 where data has to be looked up by key, SimpleDB provides a semi-structured data store with querying capability. Each object can be stored as a number of attributes where the user can search the object by the attribute name.

Similar to the concepts of “buckets “ and “objects” in S3, SimpleDB is organized as a set of “items” grouped by “domains”. However, each item can have a number of “attributes” (up to 256). Each attribute can store one or multiple values and the value must be a string (or a string array in case of multi-valued attribute). Each attribute can store up to 1K bytes, so it is not appropriate to store binary content.
SimpleDB is typically used as a metadata store in conjuction with S3 where the actual data is being stored. SimpleDB is also schema-less. Each item can define its own set of attributes and is free to add more or remove some attributes at runtime.
SimpleDB provides a query capability which is quite different from SQL. The “where” clause can only match an attribute value with a constant but not with other attributes. On the other hand, the query result only return the name of the matched items but not the attributes, which means subsequent lookup by item name is needed. Also, there is no equivalent of “order by” and the returned query result is unsorted.
Since all attribute are store as strings (even number, dates … etc). All comparison operation is done based on lexical order. Therefore, special encoding is needed for data type such as date, number to string to make sure comparison operation is done correctly.
SimpleDB is also based on an eventual consistency model like S3.
SQS – Simple Queue Service
Amazon provides a queue services for application to communicate in an asynchronous way with each other. Message (up to 256KB size) can be sent to queues. Each queue is replicated across multiple data centers.

Enterprises use HTTP protocol to send messages to a queue. “At least once” semantics is provided, which means, when the sender get back a 200 OK response, SQS guarantees that the message will be received by at least one receiver.
Receiving messages from a queue is done by polling rather than event driven calling interface. Since messages are replicated across queues asynchronously, it is possible that receivers only get some (but not all) messages sent to the queue. But the receiver keep polling the queue, he will eventually get all messages sent to the queue. On the other hand, message can be delivered out of order or delivered more than once. So the message processing logic needs to be idempotent as well as independent of message arrival order.
Once message is taken by a receiver, the message is invisible to other receivers for a period of time but it is not gone yet. The original receiver is supposed to process the message and make an explicit call to remove the message permanently from the queue. If such “removal” request is not made within the timeout period, the message will be visible in the queue again and will be picked up by subsequent receivers.
CloudWatch -- Monitoring Services
CloudWatch provides an API to extract system level metrics for each VM (e.g. CPU, network I/O and disk I/O) as well as for each load balancer services (e.g. response time, request rate). The collected metrics is modeled as a multi-dimensional data cube and therefore can be queried and aggregated (e.g. min/max/avg/sum/count) in different dimensions, such as by time, or by machine groups (by ami, by machine class, by particular machine instance id, by auto-scaling group).

This metrics is also used to drive the auto-scaling services (described below). Note that the metrics are predefined by Amazon and custom metrics (application level metrics) is not supported at this moment.
Elastic Load Balancing
Load balancer provides a way to group identical VMs into a pool. Amazon provides a way to create a software load balancer in a region and then attach EC2 instances (of the same region) to the it. The EC2 instances under a particular load balancer can be in different availability zone but they have to be in the same region.

Auto-Scaling Services
Auto-scaling allows the user to group a number of EC2 instances (typically behind the same load balancer) and specify a set of triggers to grow and shrink the group. Trigger defines the condition which is matching the collected metrics from the CloudWatch and match that against some threshold values. When match, the associated action can be to grow or shrink the group.
Auto-scaling allows resource capacity (number of EC2 instances) automatically adjusted to the actual workload. This way user can automatically spawn more VMs as the workload increases and shutdown the VM as the load decreases.
Elastic Map/Reduce
Amazon provides an easy way to run Hadoop Map/Reduce in the EC2 environment. They provide a web UI interface to start/stop a Hadoop Cluster and submit jobs to it.
Under elastic MR, both input and output data are stored into S3 rather than HDFS. This means data need to be loaded to S3 before the Hadoop processing can be started. Elastic also provides a job flow definition so user can concatenate multiple Map/Reduce job together. Elastic MR supports the program to be written in Java (jar) or any programming language (Hadoop streaming) as well as PIG and Hive.
Virtual Private Cloud
VPC is a VPN solution such that the user can extend its data center to include EC2 instances running in the Amazon cloud. Notice that this is an "elastic data center" because its size can grow and shrink when the user starts / stops EC2 instances.
User can create a VPC object which represents an isolated virtual network in the Amazon cloud environment and user can create multiple virtual subnets under a VPC. When starting the EC2 instance, the subnet id need to be specified so that the EC2 instance will be put into the subnet under the corresponding VPC.
EC2 instances under the VPC is completely isolated from the rest of Amazon's infrastructure at the network packet routing level (of course it is software-implemented isolation). Then a pair of gateway objects (VPN Gateway on the Amazon side and Customer gateway on the data center side) need to be created. Finally a connection object is created that binds these 2 gateway objects together and then attached to the VPC object.
After these steps, the two gateway will do the appropriate routing between your data center and the Amazon VPC with VPN technologies used underneath to protect the network traffic.
Things to watch out for
While Amazon AWS provides a very transparent model for enterprise to migrate their existing IT infrastructure, there are a number of limitations that needs to pay attention to …
Multicast communication is not supported
between EC2 instances. This means application has to communicate using TCP
point-to-point protocol. Some cluster replication framework based on IP
multicast simply doesn’t work in EC2 environment.
EBS currently can be attached to a single
EC2 instance. This means some application (e.g. Oracle cluster) which based on
having multiple machines accessing a shared disk simply won’t work in EC2
environment.
Except EC2, using any of the other API that
Amazon provides is lock-in to Amazon’s technology stack. This issue may be
somewhat mitigated as there are open source clone (e.g. Eucalyptus) to the
Amazon AWS services
How it works
The Google Cloud platform is the search
engine's offering to build applications, websites, store and analyze data. It
operates on a 'pay as you use' model and also offers a series of services that
are directed toward solving big data problems.

The biggest appeal to using the Google
Cloud platform is that it runs on Google's technology stack, the same one used
by the search engine to run many of their high-traffic big data applications
(e.g. Mail, Analytics, Maps, etc). This guarantees service levels offered by a
handful of providers -- in terms of availability & scalability -- as well
as access to leading-edge technology which in some cases is only available at
Google.
Getting started
The first thing you need to have is a
Google account. If at some point in time you've used any Google service, then
you already have a Google account. You can sign in to your Google account, as
well as recover access to it -- in case you forgot your password -- at:
https://accounts.google.com/ServiceLogin .
If you don't have a Google account, you can
sign up for an account at https://accounts.google.com/NewAccount . This is what
you'll need for the sign up:
- Access to your email
- Provide a password and your birthday
- Confirm a captcha and agree to the terms of service
The Google APIs Console is where you'll
manage the majority of projects running on the Google Cloud platform. A project
is a collection of information about an application, that includes such things
as: authentication information, team members email addresses and the Google
APIs an application uses. You can create your own projects, be added as a
viewer or be a developer for projects created by other people with Google
accounts. In addition, the Google APIs console is also where you'll manage and
view traffic data for a project, as well as administer billing information for
any 'pay as you use' service quotas.
Google Cloud platform services
Google Compute Engine.- Is a virtualized
server running Linux -- Ubuntu or CentOS -- entirely managed by Google. You get
absolute control of the server operating system (OS), like any other virtual
server and you also gain access to most of the features offered by large
virtual server providers, including: public IP address support, ability to
start and stop instances to fulfill workloads at will, tools and APIs to
automate server administration, as well as 'pay as you use' billing.

Depending on your circumstances and the
type of big data application you plan on running, Google Compute Engine offers
four different type of virtual servers. The lowest being the n1-standard-1-d
configuration with 1 virtual core & 3.75 GB of memory and the largest the
n1-standard-8-d configuration with 8 virtual cores and 30 GB of memory, with
the two other configurations being in between these last two. Every Google Cloud
Compute Engine instance is offered at different price points -- the more
resources, the higher its hourly price. More importantly though is the ability
to start and shutdown different instances at your discretion, something that
allows you to adjust the type of Google Compute Engine instance in a very short
time, as well as only pay for server resources you use.
The Google Compute Engine also supports
multiple storage types. By default, the data used on a Google Compute Engine
instance is assumed to be short lived and the moment a server -- technical the
virtual machine(VM) -- is stopped, all data is lost. This storage is called
ephemeral disk storage, of which a predetermined amount of space is assigned
depending on the size of an instance. For cases where you wish to conserve data
for a longer period (i.e. after a VM is stooped) Google Compute Engine also
supports persistent disk storage where data is stored for days or months
without the need to pay for a running Google Compute Engine instance, but rather
a Google Compute Engine instance can later be attached to the persisted data.
Persistent disk storage requires an additional payment, unlike ephemeral disk
storage which is included in the hourly fee of a Google Comput Engine instance.
Finally, Google Compute Engine instances can also work with data from Google
Cloud Storage. Google Cloud Storage is another service of the Google Cloud
platform -- which I'll describe shortly -- that would also incur in a separate
bill -- like persistent disk storage.
At the time of this writing, the Google
Compute Engine service requires an additional sign up process. This means
you'll require additional approval -- besides having a Google Account -- and
you'll also need to pay quotas from day one (i.e. just to try it out).
Google Cloud Storage.- Is a storage service
that allows you to skip low-level tasks associated with classical storage
systems (e.g. Relational databases & regular files). It works entirely on
the web, which means that any web-enabled application can interact directly
with Google Cloud Storage, as well as perform operations on it (i.e. create,
read, update and delete data) via standard REST web services.

From the perspective of big data, Google
Cloud Storage is very practical for managing large files. With Google Cloud
Storage there are no web servers to maintain (for downloads) or FTP servers
(for uploads), there is also no notion of the actual file type or its contents.
In Google Cloud Storage everything is treated as objects -- essentially just
'chunks' of data -- that are transferred and retrieved using the web's
protocols. And with the capability for storing objects from 1 byte up to 5 TB
(Terabytes), Google Cloud Storage can be a handy service for big data
operations.
Applicable toward the first Google project
enabled with Google Cloud Storage you'll get the following free quotas: 5 GB of
storage, 25 GB of download bandwidth, 25 GB of upload bandwidth, 30,000
GET/HEAD requests, as well as 3,000 PUT/POST/GET bucket and service requests.
In addition, data residing on Google Cloud Storage can also be leveraged with
other Google Cloud services, that include: Google App Engine, Google BigQuery
API and the Google Prediction API.
Google Cloud SQL.- Is a service that allows
you to operate a relational database management system (RDBMS) based on the
capabilities of MySQL running on Google's infrastructure -- MySQL is one of the
more popular open source RDBMS. Similar to other Google Cloud services, the
biggest plus of using Google Cloud SQL is that you avoid having to deal with
the system administration overhead involved in running a relational database
management system (RDBMS).
In many situations, big data applications
grow from using a small manageable RDBMS to a big RDBMS with many growing pains
(e.g. space management, resource limits, backup and recovery). So if your big
data applications are going to work with a RDBMS and not with a newer data
storage technology (i.e. NoSQL), Google Cloud SQL can be a good option. Be aware
though that the size limit for individual database instances is 10 GB, in
addition Google Cloud SQL is also not a drop-in replacement for a MySQL
database (e.g. there are some features that are part of MySQL but aren't
available on Google Cloud SQL).
Google Cloud SQL is available under two
plans with four tiers each. The tiers include D1,D2,D4 and D8 instances, with
their primary feature being 0.5, 1, 2 and 4 GB of RAM per instance,
respectively. In addition, proportional amounts of storage and I/O operations
are also assigned depending on the tier. The plans for each of these tiers are
available in either a package plan -- with monthly quotas and a monthly bill --
or under a per use plan -- with per hour and unit quotas and 'pay as you use'
bill. And like other Google cloud services, Google Cloud SQL is tightly
integrated to work with other services like the Google App Engine.
Google App Engine.- The Google App Engine
is a platform for building applications to run on Google's infrastructure.
Unlike the prior Google Cloud services that provide standalone application
services (e.g. Google Compute Engine offers a virtual Linux server, Google
Cloud storage space to store files,etc), the Google App Engine is an end-to-end
solution for building applications. This means you design and build
applications to run on the Google App Engine from the start. Although this
increases the learning curve and limits the options for building an application
(e.g. you can't install any software you wish on the Google App Engine, as if
it were an OS like the Google Compute Engine), there's the upside of not having
to worry about issues like application scaling, deployment and system
administration.

Since the Google App Engine is a platform,
its applications are built around a set of blueprints or APIs. The Google App
Engine is supported in three programming languages: Python, Java or Go -- the
last of which is a Google programming language. For each of these languages
Google provides a SDK (Software Development Kit) on which you design, build and
test applications on your local workstation. After you're done on your local
workstation, you upload applications to the Google App Engine so end users are
able to access your applications -- all applications built with one of the SDKs
are compatible and uploaded to the same Google App Engine.
The Google App Engine also supports a
series of storage mechanisms to archive an application's data. The default
Google App Engine datastore provides a NoSQL schemaless object datastore, with
a query engine and atomic transactions. The Google Cloud SQL service is another
alternative that provides a relational SQL database based on the MySQL RDBMS.
In addition, the Google Cloud Storage service is also available, providing a
storage service for objects and files up to 5 terabytes in size.
Unlike other Google Cloud services managed
on the Google APIs console, the Google App Engine has its own administrative
console available at https://appengine.google.com . The Google App Engine is
also available in three price tiers: free, paid and premiere. Each of the three
tiers have free daily quotas, that include: 28 instance hours, 1GB of outgoing
& incoming bandwidth, 1 GB of app engine datastore, as well as other
resources like I/O operations and outgoing emails. For all tiers, each of these
quotas are reset on a daily basis. The biggest difference of the free tier
among the other two tiers is that in case an application consumes its daily
quotas, you're not allowed to buy additional quotas.
On the free tier if daily resources for the
Google App Engine are consumed, an application simply stops or throws an error
(e.g.'Resource not available'). This means that if you're expecting a
considerable amount of traffic, you should consider the paid or premiere tiers,
both of which allow you to purchase additional 'pay as you use' quotas. The
paid tier incurs in a minimum spend limit -- at the time of this writing of
$2.10/week -- toward 'pay as you use' quotas, this means that whether your
application consumes its daily quotas or not, you'll be charged a minimum of $9
per month/per application. The premiere tier is designed for cases in which you
plan to deploy multiple applications and incurs in a charge of $500 per
month/per account. The price difference between the paid and premiere tiers is
the premiere account is billed per account -- with any number of applications
-- and also includes operational support from Google, support which is not
included in the other two tiers.
Google BigQuery Service.- Is a service that allows you
to analyze large amounts of data, into the Terabyte range. It's essentially an
analytics service that can execute SQL-like queries against datasets with
billions of rows. BigQuery works with datasets and tables, where a dataset is a
collection of one or more tables and tables are standard two-dimensional data
tables. Queries on datasets/tables are done from either a browser or from a
command line, similar to other Google Cloud storage technologies.

Though BigQuery sounds similar to a RDBMS
or a service like Google Cloud SQL, since it also uses SQL-like queries and
operates on two-dimensional data tables, it's different. The primary purpose of
BigQuery is to analyze big data, therefore it's not well suited for constantly
saving or updating data, as it's typically done on RDBMS that back most web
applications. BigQuery is intended as a 'store once' storage system that's
consulted over and over again to obtain insights from big data sets -- similar
to the way data warehouses or data marts operate.
BigQuery offers free monthly quotas for the
first 100 GB of data processing. And since BigQuery uses a columnar data
structure, it means that for a given query you're only charged for data
processed on each column, not the entire table -- meaning 100 GB can go a long
way toward doing queries. In addition, BigQuery can interact with data residing
on Google Cloud Storage and it also offers a series of sample data tables which
can serve to do analytics on certain big data sets or be used to test out the
service, these sample data includes: Samples from US weather stations since
1929, measurement data of broadband connection performance, birth information
for the United States from 1969 to 2008, word index for works of Shakespeare or
revision information for Wikipedia articles.
Prediction API.- Is a service that allows
you to predict behaviors from data sets using either a regression model or a
categorical model. The prediction API uses pattern-matching and machine
learning under-the-hood so you can avoid the programming required to undergo
regression or categorical models. Like any other prediction tool, the greater
the sample data -- or training data as it's called in the Prediction API -- the
greater the accuracy of a prediction.
The prediction API always requires you
provide it with training data -- numbers or strings -- so it can provide you
with answers to queries you want to predict. For example, by running a
regression model on the prediction API it compares a given query to training
data and predicts a value, based on the closeness of existing examples (e.g.
for a data set containing commute times for multiple routes, predict the time
for a new route). By running a categorical model on the prediction API it
determines the closest category fit for a given query among all the existing
examples provided in the training data (e.g. for a data set containing emails
defined as spam and non-spam, predict if a new email is spam or non-spam).
Regression models in the prediction API return numeric values as the result,
where as categorical models return string values as the result.
The prediction API can interact with data
residing on Google Cloud Storage and is also free for the first six months up
to 20,000 predictions. In addition, the free period is limited to the following
daily quotas: 100 predictions/day and 5MB trained/day. For usage of the
prediction API beyond the free sixth month period or the free daily quotas,
'pay as you use' quotas are applied.
Translate API.- Is a tool to translate or
detect text from over 60 different languages. The API is usable with either
standard REST services or using REST from JavaScript (i.e. directly from a web
page). Language translation and detection quotas are calculated in millions of
characters. At the time of this writing, the price for translating or detecting
1 millions characters is $20, where the charges are adjusted in proportion to
the number of characters actually provided (i.e. spaces aren't counted). By
default, there's a limit of 2 million characters a day of processing, but this
limit is adjustable up to 50 million characters a day from the Google APIs
console.
