What is Amazon Web Services?
AWS provides a flexible, cost-effective,
scalable, and easy-to-use cloud computing platform that is suitable for
research, educational use, individual use, and organizations of all sizes. It’s
easy to access AWS cloud services via the Internet. Because the AWS cloud
computing model allows you to pay for services on-demand and to use as much or
as little at any given time as you need, you can replace up-front capital
infrastructure expenses with low variable costs that scale as your needs
change. AWS offers services in many areas to fit your needs, as shown in the
diagram.

EC2 – Elastic Computing
Amazon has procured a large number of commoditized Intel boxes running virtualization software Xen. On top of Xen, Linux or Windows can be run as the guest OS . The guest operating system can have many variations with different set of software packages installed.

Each configuration is bundled as a custom machine image (called AMI). Amazon host a catalog of AMI for the users to choose from. Some AMI is free while other requires a usage charge. User can also customize their own setup by starting from a standard AMI, make their special configuration changes and then create a specific AMI that is customized for their specific needs. The AMIs are stored in Amazon’s storage subsystem S3.
Amazon also classifies their machines in terms of their processor power (no of cores, memory and disk size) and charged their usage at a different rate. These machines can be run in different network topology specified by the users. There is an “availability zone” concept which is basically a logical data center. “Availability zone” has no interdependency and is therefore very unlikely to fail at the same time. To achieve high availability, users should consider putting their EC2 instances in different availability zones.
“Security Group” is the virtual firewall of Amazon EC2 environment. EC2 instances can be grouped under “security group” which specifies which port is open to which incoming range of IP addresses. So EC2 instances that running applications at various level of security requirements can be put into appropriated security groups and managed using ACL (access control list). Somewhat very similar to what network administrator configure their firewalls.
User can start the virtual machine (called an EC2 instance) by specifying the AMI, the machine size, the security group, and its authentication key via command line or an HTTP/XML message. So it is very easy to startup the virtual machine and start running the user’s application. When the application completes, the user can also shutdown the EC2 instance via command line or HTTP/XML message. The user is only charged for the actual time when the EC2 instance is running.
One of the issue of extremely dynamic machine configuration (such as EC2) is that a lot of configuration setting is transient and does not survive across reboot. For example, the node name and IP address may have been changed, all the data stored in local files is lost. Latency and network bandwidth between machines may also have changed. Fortunately, Amazon provides a number of ways to mitigate these issues
- By paying some charge, user can reserve a stable IP address, called “elastic IP”, which can be attached to EC2 instance after they bootup. External facing machine is typically done this way.
- To deal with data persistence, Amazon also provides a logical network disk, called “elastic block storage” to store the data. By paying some charges, EBS is reserved for the user and it survives across EC2 reboots. User can attach the EBS to EC2 instances after the reboot.
S3 – Simple Storage Service
Amazon S3 provides a HTTP/XML services to save and retrieve content. It provides a file system-like metaphor where “objects” are group under “buckets”. Based on a REST design, each object and bucket has its own URL.
With HTTP verbs (PUT, GET, DELETE, POST), user can create a bucket, list all the objects within the bucket, create object within a bucket, retrieve an object, remove an object, remove a bucket … etc.
Under S3, each object has a unique URI which serves as its key. There is no query mechanism in S3 and User has to lookup the object by its key. Each object is stored as an opaque byte array with maximum 5GB size. S3 also provides an interesting partial object retrieval mechanism by specifying the ranges of bytes in the URL.
However, partial put is not current support but it can be simulated by breaking the large object into multiple small objects and then do the assembly at the app level. Breaking down the object also help to speed up the upload and download by doing the data transfer in parallel.
Within Amazon S3, each S3 objects are replicated across 2 (or more) data center and also cache at the edge for fast retrieval.
Amazon S3 is based on an “eventual consistent” model which means it is possible that an application won’t see the change it just made. Therefore, some degree of tolerance of inconsistent view is required by the application. Application should avoid the situation of having two concurrent modifications to the same object. And application should wait for some time between updates, and also should expect all the data it reads is potentially stale for few seconds.
There is also no versioning concept in S3, but it is not hard to build one on top of S3.
EBS – Elastic Block Storage
Based on RAID disks, EBS provides a persistent block storage device for data persistence where user can attach it to a running EC2 instance within the same availability zone. EBS is typically used as a file system that is mounted to EC2 instance, or as raw devices for database.
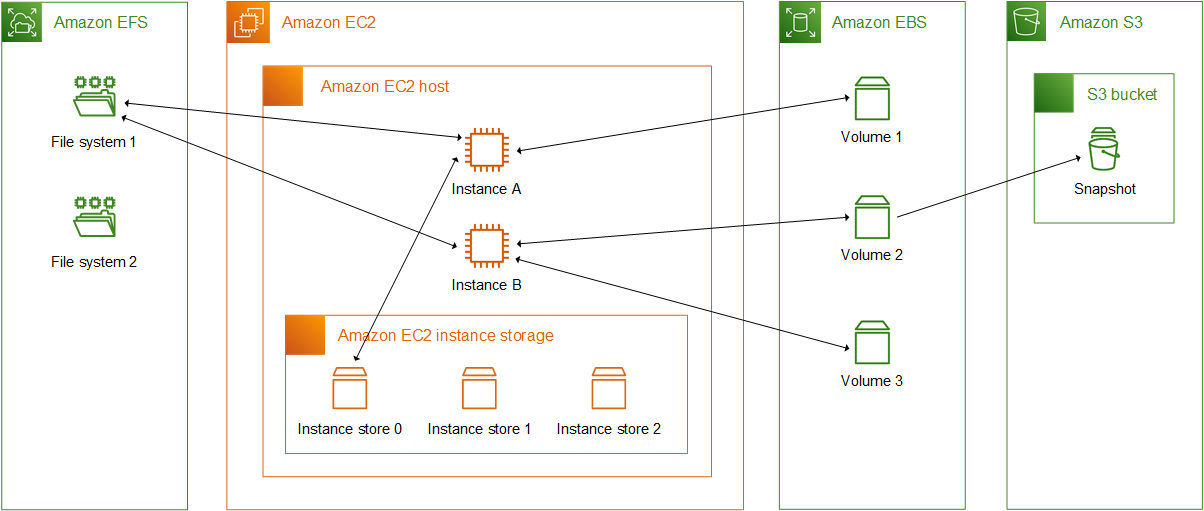
Although EBS is a network devices to the EC2 instance, benchmark from Amazon shows that it has higher performance than local disk access. Unlike S3 which is based on eventual consistent model, EBS provides strict consistency where latest updates are immediately available.
SimpleDB – queriable data storage
Unlike S3 where data has to be looked up by key, SimpleDB provides a semi-structured data store with querying capability. Each object can be stored as a number of attributes where the user can search the object by the attribute name.

Similar to the concepts of “buckets “ and “objects” in S3, SimpleDB is organized as a set of “items” grouped by “domains”. However, each item can have a number of “attributes” (up to 256). Each attribute can store one or multiple values and the value must be a string (or a string array in case of multi-valued attribute). Each attribute can store up to 1K bytes, so it is not appropriate to store binary content.
SimpleDB is typically used as a metadata store in conjuction with S3 where the actual data is being stored. SimpleDB is also schema-less. Each item can define its own set of attributes and is free to add more or remove some attributes at runtime.
SimpleDB provides a query capability which is quite different from SQL. The “where” clause can only match an attribute value with a constant but not with other attributes. On the other hand, the query result only return the name of the matched items but not the attributes, which means subsequent lookup by item name is needed. Also, there is no equivalent of “order by” and the returned query result is unsorted.
Since all attribute are store as strings (even number, dates … etc). All comparison operation is done based on lexical order. Therefore, special encoding is needed for data type such as date, number to string to make sure comparison operation is done correctly.
SimpleDB is also based on an eventual consistency model like S3.
SQS – Simple Queue Service
Amazon provides a queue services for application to communicate in an asynchronous way with each other. Message (up to 256KB size) can be sent to queues. Each queue is replicated across multiple data centers.

Enterprises use HTTP protocol to send messages to a queue. “At least once” semantics is provided, which means, when the sender get back a 200 OK response, SQS guarantees that the message will be received by at least one receiver.
Receiving messages from a queue is done by polling rather than event driven calling interface. Since messages are replicated across queues asynchronously, it is possible that receivers only get some (but not all) messages sent to the queue. But the receiver keep polling the queue, he will eventually get all messages sent to the queue. On the other hand, message can be delivered out of order or delivered more than once. So the message processing logic needs to be idempotent as well as independent of message arrival order.
Once message is taken by a receiver, the message is invisible to other receivers for a period of time but it is not gone yet. The original receiver is supposed to process the message and make an explicit call to remove the message permanently from the queue. If such “removal” request is not made within the timeout period, the message will be visible in the queue again and will be picked up by subsequent receivers.
CloudWatch -- Monitoring Services
CloudWatch provides an API to extract system level metrics for each VM (e.g. CPU, network I/O and disk I/O) as well as for each load balancer services (e.g. response time, request rate). The collected metrics is modeled as a multi-dimensional data cube and therefore can be queried and aggregated (e.g. min/max/avg/sum/count) in different dimensions, such as by time, or by machine groups (by ami, by machine class, by particular machine instance id, by auto-scaling group).

This metrics is also used to drive the auto-scaling services (described below). Note that the metrics are predefined by Amazon and custom metrics (application level metrics) is not supported at this moment.
Elastic Load Balancing
Load balancer provides a way to group identical VMs into a pool. Amazon provides a way to create a software load balancer in a region and then attach EC2 instances (of the same region) to the it. The EC2 instances under a particular load balancer can be in different availability zone but they have to be in the same region.

Auto-Scaling Services
Auto-scaling allows the user to group a number of EC2 instances (typically behind the same load balancer) and specify a set of triggers to grow and shrink the group. Trigger defines the condition which is matching the collected metrics from the CloudWatch and match that against some threshold values. When match, the associated action can be to grow or shrink the group.
Auto-scaling allows resource capacity (number of EC2 instances) automatically adjusted to the actual workload. This way user can automatically spawn more VMs as the workload increases and shutdown the VM as the load decreases.
Elastic Map/Reduce
Amazon provides an easy way to run Hadoop Map/Reduce in the EC2 environment. They provide a web UI interface to start/stop a Hadoop Cluster and submit jobs to it.
Under elastic MR, both input and output data are stored into S3 rather than HDFS. This means data need to be loaded to S3 before the Hadoop processing can be started. Elastic also provides a job flow definition so user can concatenate multiple Map/Reduce job together. Elastic MR supports the program to be written in Java (jar) or any programming language (Hadoop streaming) as well as PIG and Hive.
Virtual Private Cloud
VPC is a VPN solution such that the user can extend its data center to include EC2 instances running in the Amazon cloud. Notice that this is an "elastic data center" because its size can grow and shrink when the user starts / stops EC2 instances.
User can create a VPC object which represents an isolated virtual network in the Amazon cloud environment and user can create multiple virtual subnets under a VPC. When starting the EC2 instance, the subnet id need to be specified so that the EC2 instance will be put into the subnet under the corresponding VPC.
EC2 instances under the VPC is completely isolated from the rest of Amazon's infrastructure at the network packet routing level (of course it is software-implemented isolation). Then a pair of gateway objects (VPN Gateway on the Amazon side and Customer gateway on the data center side) need to be created. Finally a connection object is created that binds these 2 gateway objects together and then attached to the VPC object.
After these steps, the two gateway will do the appropriate routing between your data center and the Amazon VPC with VPN technologies used underneath to protect the network traffic.
Things to watch out for
While Amazon AWS provides a very transparent model for enterprise to migrate their existing IT infrastructure, there are a number of limitations that needs to pay attention to …
Multicast communication is not supported
between EC2 instances. This means application has to communicate using TCP
point-to-point protocol. Some cluster replication framework based on IP
multicast simply doesn’t work in EC2 environment.
EBS currently can be attached to a single
EC2 instance. This means some application (e.g. Oracle cluster) which based on
having multiple machines accessing a shared disk simply won’t work in EC2
environment.
Except EC2, using any of the other API that
Amazon provides is lock-in to Amazon’s technology stack. This issue may be
somewhat mitigated as there are open source clone (e.g. Eucalyptus) to the
Amazon AWS services

0 comments:
Post a Comment